DATA310_Public
Response for Class on 7/9
Question 1:
What is TF Hub? How did you use it when creating your script for “text classification of movie reviews”?
Answer:
TF Hub is a platform that enables data to be transferred from the cloud to our individual computers or other local devices. When using it we are able to bring the movie reviews database/module from the cloud into our pycharm environment.
Question 2:
What are the optimizer and loss functions? How good was your “text classification of movie reviews” model?
Answer:
The loss function shows the accuracy of a model. The network takes a guess at the relationship between x and y. Then it measures the loss produces the value/error of the guessed relationship. This process is repeated in alignment with the number of epochs assigned. Each epoch the data is passed through the optimizer which will minimize the errors. Overall, after each epoch the loss should be decreasing as the accuracy is increase because the networks “guess” should be getting closer and closer to the correct answer. Specifically, the text classification of movie reviews test set had an accuracy of 0.855 with a loss of 0.320.
Question 3:
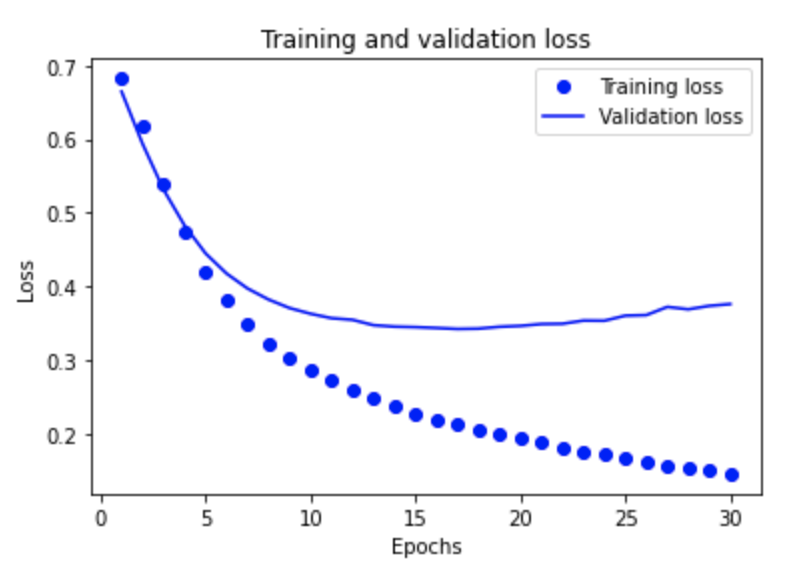
In “text classification with preprocessed text” you produced a graph of training and validation loss. Add the graph to this response and provide a brief explanation.
Answer:
The graph shows that as the number of epochs performed increases the loss decreases; however, the validation loss appears to level out at 10 epochs with a loss value of about 0.35.
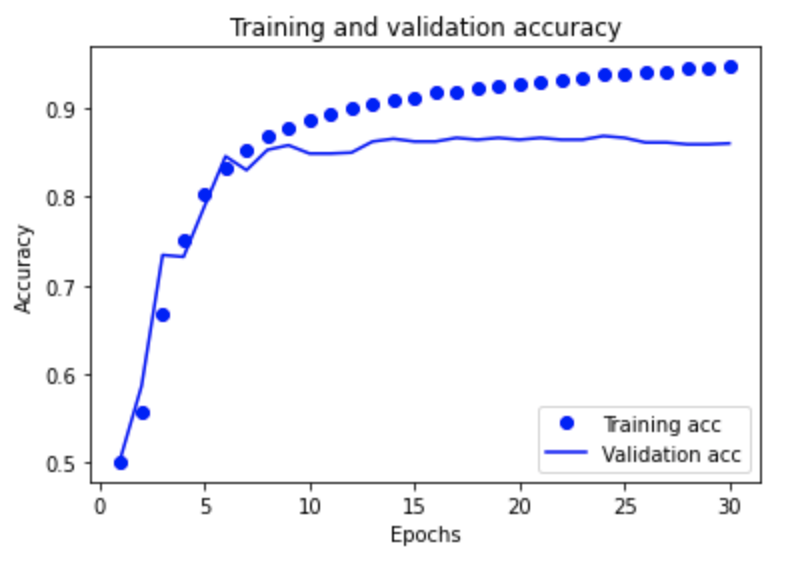
Question 4:
Likewise do the same for the training and validation accuracy graph.
Answer:
The graph shows that as the number of epochs are performed increases, the accuracy also increases; however, like with the loss graph the increase in accuracy becomes much more gradual after about 10 epochs.